Go 的逃逸分析
逃逸是怎么发生的?
这里先来看下 Go 的逃逸分析机制,在编译原理中,分析指针动态范围的方法称之为逃逸分析。通俗来讲,当一个对象的指针被多个方法或线程引用时,我们称这个指针发生了逃逸。
Go 语言的逃逸分析是编译器执行静态代码分析后,对内存管理进行的优化和简化,它可以决定一个变量是分配到堆还栈上。
Go 语言逃逸分析最基本的原则是:如果一个函数返回对一个变量的引用,那么它就会发生逃逸。简单来说,编译器会分析代码的特征和代码生命周期,Go 中的变量只有在编译器可以证明在函数返回后不会再被引用的,才分配到栈上,其他情况下都是分配到堆上。
编译器会根据变量是否被外部引用来决定是否逃逸:
- 如果函数外部没有引用,则优先放到栈中;
- 如果函数外部存在引用,则必定放到堆中;
- 如果栈上放不下,则必定放到堆上;
以下举个逃逸的例子:
func foo() *int {
t := 3
return &t
}
这里 t 是局部变量所以正常情况是放在栈中的,但是这里返回了这个变量的指针,所以发生了逃逸
逃逸场景
指针逃逸
当一个指针从函数内部逃逸到函数外部时,我们称之为指针逃逸。这种情况通常发生在将指针作为函数的返回值或存储到全局变量中时。
下面是一个简单的示例代码,展示了指针逃逸的情况:
package main
type Person struct {
Name string
Age int
}
func createPerson(name string, age int) *Person {
p := Person{Name: name, Age: age}
return &p
}
func main() {
person := createPerson("John", 30)
_ = person
}
当我们执行 go build -gcflags=-m 来分析逃逸情况时,编译器将给出相应的提示。下面是执行上述命令后的输出:
./main.go:7:9: &p escapes to heap
编译器告诉我们,变量 &p 逃逸到了堆上。
解释分析过程:
- 第一步,编译器将编译源代码并进行静态分析。
- 编译器发现 createPerson 函数返回了指向局部变量 p 的指针
&p。 - 由于
&p是指向局部变量的指针,并且在函数外部被使用(赋值给 person 变量),编译器确定该指针将在函数外部继续使用,因此它会逃逸到堆上。 - 编译器生成的提示
&p escapes to heap表明指针&p逃逸到了堆上分配。
这个例子展示了指针逃逸的情况。编译器的逃逸分析能够帮助我们了解代码中的逃逸行为,帮助我们进行性能优化和内存管理。通过使用 -gcflags=-m 标志来分析逃逸情况,我们可以获得关于逃逸发生的详细信息,从而优化代码以减少逃逸和堆分配的情况。
栈空间不足逃逸
下面是一个示例代码,展示了当栈空间不足时,变量会逃逸到堆上分配的情况:
package main
type LargeStruct struct {
Data [1 << 20]int
}
func createLargeStruct() *LargeStruct {
l := LargeStruct{}
return &l
}
func main() {
largeStruct := createLargeStruct()
_ = largeStruct
}
在这个例子中,我们定义了一个非常大的结构体 LargeStruct,它包含一个大小为 1MB 的整数数组。createLargeStruct 函数创建了一个 LargeStruct 类型的局部变量 l,然后返回指向 l 的指针。
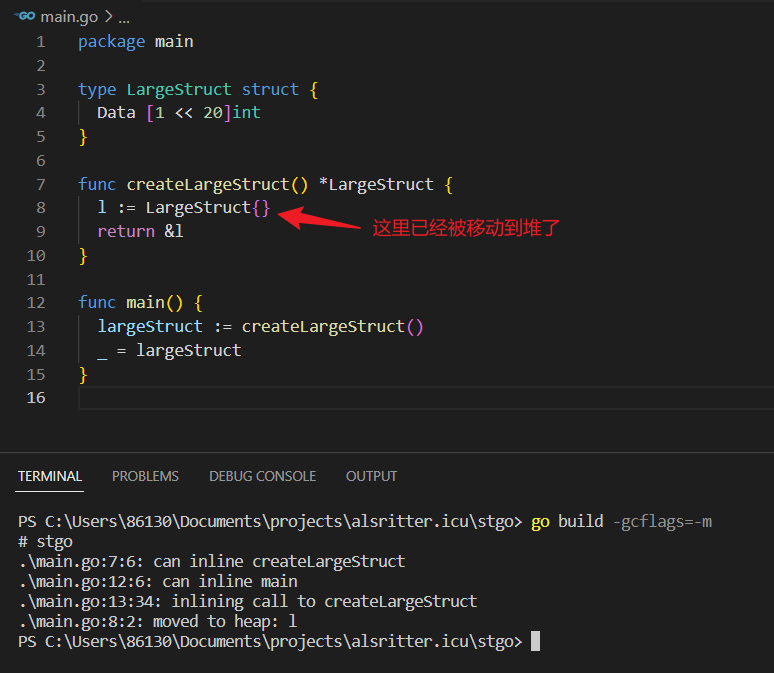
在 Go 中,栈的大小是由编译器和操作系统决定的,并且可以根据具体的编译器和操作系统进行配置。因此,没有一个固定的结构体大小来确定何时会导致栈空间不足而发生逃逸。
栈的大小通常在几兆字节的范围内,但实际的大小可能因操作系统、架构和编译器的不同而有所不同。一般来说,当一个结构体的大小超过栈的限制时,它很可能会发生逃逸,被分配到堆上。
需要注意的是,栈空间不足而导致逃逸的情况并不仅仅取决于结构体的大小,还取决于函数的调用层次、局部变量的数量以及其他因素。在一些递归或高度嵌套的函数调用中,即使结构体的大小相对较小,也有可能发生栈空间不足而逃逸的情况。
为了避免栈空间不足导致的逃逸,可以考虑以下几个方面:
减小结构体的大小:优化结构体的字段,去除不必要的字段或对齐填充,以减小结构体的大小。
使用指针或引用:将大型结构体改为指针或引用,使其在栈上存储指针而不是整个结构体。
减少函数调用层次:尽量减少函数调用的层次和深度,以减小栈空间的使用。
综上所述,并没有一个明确的结构体大小来确定栈空间不足而发生逃逸的阈值。要确保代码的健壮性和可靠性,应该理解栈的大小限制,并根据具体情况设计和管理结构体的大小和使用方式。
动态类型逃逸
动态类型的使用可以导致变量逃逸到堆上。下面是一个示例代码,展示了动态类型导致逃逸的情况:
package main
func createDynamicValue() interface{} {
var value interface{}
value = 42
return value
}
func main() {
dynamicValue := createDynamicValue()
_ = dynamicValue
}
在这个例子中,createDynamicValue 函数创建了一个接口类型的变量 value,并将其赋值为整数 42。由于接口类型可以保存任意类型的值,这里的 value 是一个动态类型的变量。
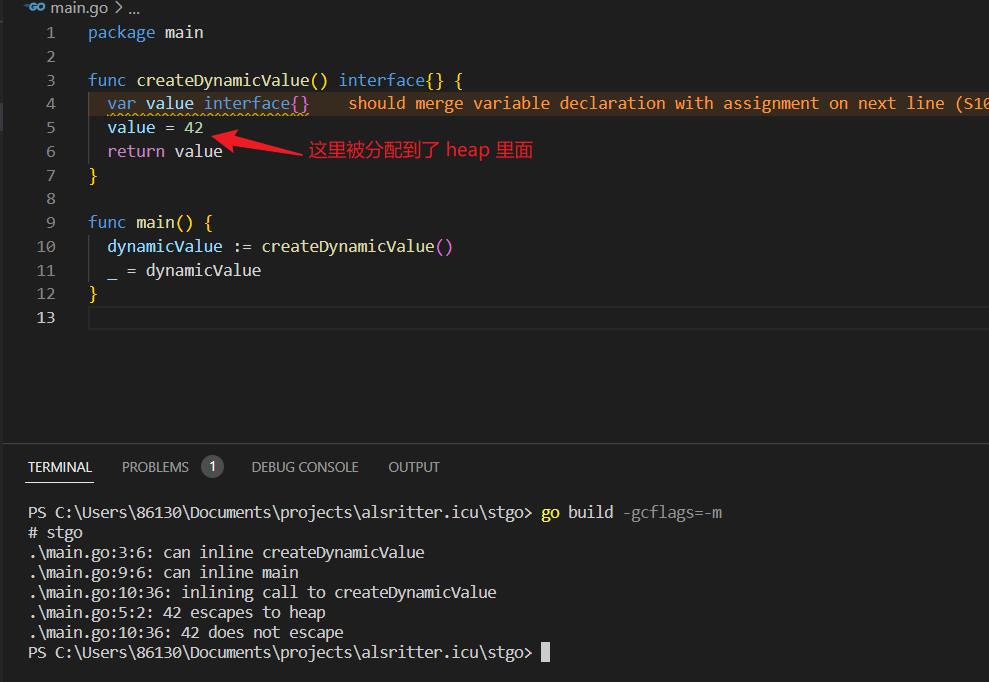
编译器告诉我们,变量 value 逃逸到了堆上。
解释分析过程:
- 第一步,编译器将编译源代码并进行静态分析。
- 编译器发现 createDynamicValue 函数返回了一个接口类型的变量 value。
- 由于接口类型的变量可以存储任意类型的值,编译器无法在编译时确定 value 的具体类型。因此,它将 value 视为动态类型,需要在堆上分配空间以容纳其值。
- 编译器生成的提示表明变量 value 逃逸到了堆上分配。
这个例子展示了动态类型导致变量逃逸到堆上的情况。当使用接口类型或其他动态类型时,编译器无法在编译时确定变量的具体类型,因此需要将其逃逸到堆上进行动态分配。了解这种情况可以帮助我们设计更有效的数据结构和算法,以避免不必要的逃逸和堆分配。
闭包引用对象逃逸
闭包引用对象时,如果该对象在闭包函数外部被使用,会导致对象逃逸到堆上。下面是一个示例代码,展示了闭包引用对象导致逃逸的情况:
package main
type Person struct {
Name string
Age int
}
func createClosure() func() *Person {
p := &Person{Name: "John", Age: 30}
return func() *Person {
return p
}
}
func main() {
closure := createClosure()
person := closure()
_ = person
}
在这个例子中,我们定义了一个 Person 结构体,然后在 createClosure 函数中创建了一个闭包函数,该闭包函数引用了变量 p,即一个 Person 类型的指针。闭包函数返回了对 p 的引用。
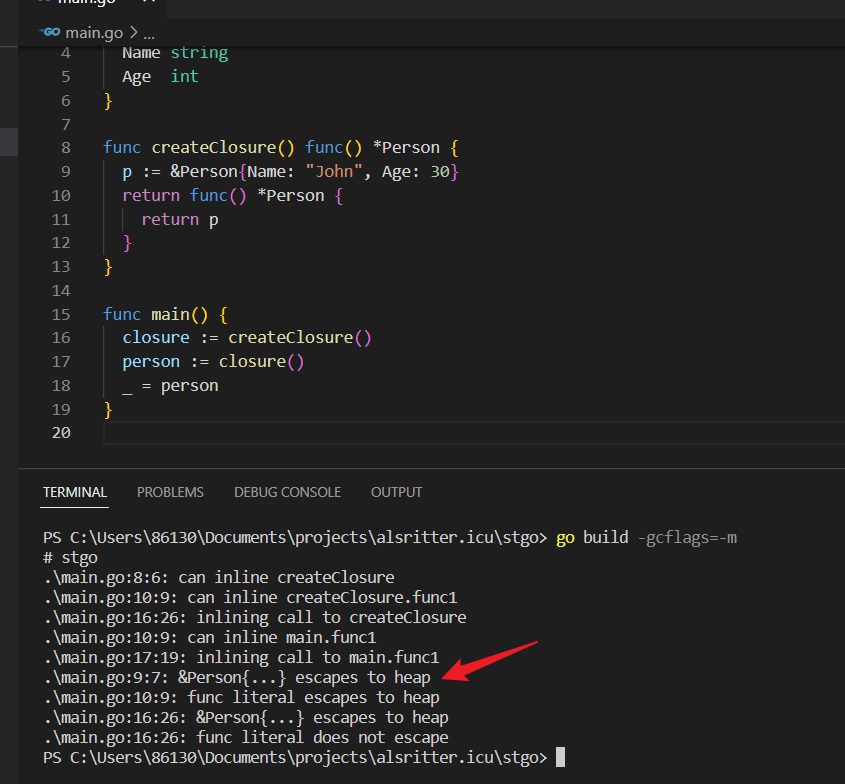
解释分析过程:
- 第一步,编译器将编译源代码并进行静态分析。
- 编译器发现 createClosure 函数返回了闭包函数,该闭包函数引用了变量 p。
- 由于闭包函数返回了对 p 的引用,并且在函数外部被使用(赋值给 person 变量),编译器确定该变量将在函数外部继续使用,因此它会逃逸到堆上。
- 编译器生成的提示 p escapes to heap 表明变量 p 逃逸到了堆上分配。
这个例子展示了闭包引用对象导致对象逃逸到堆上的情况。当闭包函数持有对某个对象的引用,并且该对象在闭包函数外部被使用时,编译器会将该对象逃逸到堆上分配。了解这种情况可以帮助我们在使用闭包时更好地管理对象的生命周期和内存分配。
Goroutine 逃逸
这个是和上面一样的